Reinforcement Learning in Gaming
Microsoft made an amazing history in machine learning (ML) and artificial intelligence (AI). They proudly announced the preview of Reinforcement Learning (RL) on Azure Machine Learning at Build 2020. Today, the research project between Microsoft Research and Ninja Theory aims to leverage state-of-the-art RL in gaming, more specifically, how well agents can learn to collaborate with human players.
So, what is reinforcement learning?
Reinforcement learning is a machine learning paradigm that trains the policy of the agent so that it can make a sequence of decisions. The aim of the agent is to output actions according to the observation it makes about its environment. These actions then lead to more observations and rewards. Training involves numerous trial-and-error runs as the agent interacts with the environment, and in each iteration, it is able to improve the policy.

This learning approach became very popular in recent years, since these agents perform complex tasks really well thanks to RL, causing real breakthroughs in the field. There are many use cases in the world, which use this technology, in the areas such as robotics, chemistry, and a lot more; but the focus of this article is game development.
In the context of video games, the agent that takes actions or performs a behavior is the game agent. Think of a character or a bot in a game, it has to understand the state of the game, and where are the players, and then based on this observation, it should make a decision based on the situation of the game. In RL, decisions are driven by rewards, which in a game could be provided as a high score or a new level for reaching a specific goal. The cool thing about a gaming situation is that the policy of the agent is trained under the pressure of the game. For example, it could learn what to do when it’s being attacked, or how to behave in order to reach a specific goal.
Reinforcement Learning in Azure Machine Learning
Microsoft Research worked together with Ninja Theory to explore new possibilities of RL in gaming. Project Paidia was announced on the 3rd of August at Game Stack Live, and the state-of-the-art AI agents used Bleeding Edge as a research environment.
The aim of the research is not to build an agent that is able to beat humans (just like the famous chess agent), but to provide game developers tools to make them able to apply RL while building exciting games for their players.
If you are ready to get started with RL in gaming, check out the sample notebooks to train an agent, for example, to navigate a lava maze in Minecraft using Azure Machine Learning.

The goal of this agent is to reach the blue tiles while navigating through this maze by walking only on solid tiles. The agent might fall into the lava in which case it has to start it over. Since the maps are generated randomly, the agent also has to learn how to generalize and adapt.
Let’s look into an example of how an agent can be trained with Azure Machine Learning in a simple gaming environment. The new RL support in Azure Machine Learning services provides scalability while training to CPU or GPU-enabled virtual machines with ML compute clusters that can automatically provision, manage, and scale these virtual machines. You can use Single Agent or Multi Agent RL for your training scenarios. You can use different gaming environments, for example, Open AI Gym. You can build your models with TensorFlow, and PyTorch deep learning frameworks, and supports ONNX too. You can also track your experiments and monitor the runs. Azure provides numerous AI solutions to build, run, and grow your games. Accelerate your games with AI and ML to provide more realistic worlds and challenges.
Training in a Multi Agent scenario
For this tutorial, we use the following situation: The blue circles are the agents, and they start spreading around and observing their environment while finding the landmarks, that are shown as black circles.

They get rewarded if they find the landmarks without overlapping while spreading around. For this, we use Open AI Gym’s Particle environment within Azure Machine Learning workspace. You will need an Azure subscription, a resource group, and a workspace with a computation cluster in the resource group to follow this tutorial. When your resource is deployed, launch the workspace from the overview of the resource. Go to Manage -> Compute menu on the left side and click New. Give it a name (I call it RLCompute0) and set it to use GPU, choose for example STANDARD_NC4 , then on the scheduling page set up auto shut down, which is a good idea so it will not create expenses when not in use. You can define security settings on the next tab, and on the Applications tab you can add custom applications to run when your compute starts up. Finally, you can add additional tags to categorize your resource, and after reviewing you resource and found it correct, click Create.
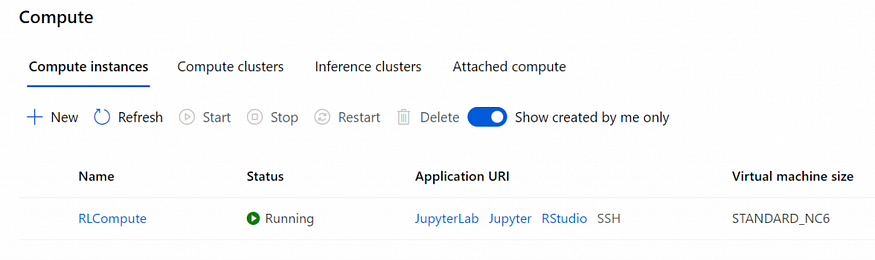
Now go to Authoring -> Notebooks menu on the left, create a files folder, and place in the folder all the files that you can find in this GitHub folder. When you are ready, let’s move back to the main folder, and create a new IPython notebook by choosing three dots when hovering over the main folder.
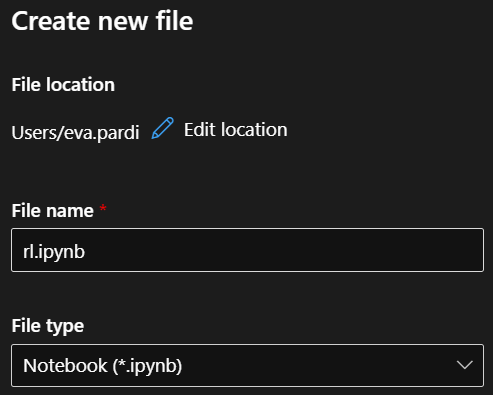
Give it a name, make sure the file type is .ipynb, open it, and let’s start coding! As the kernel, choose Python 3.8 – AzureML for Python SDK v1, and Python 3.10 – SDK v2 for Python SDK v2.
# We recommend updating pip to the latest version.
!pip install --upgrade pip
# Update matplotlib for plotting charts
!pip install --upgrade matplotlib
# Update Azure Machine Learning SDK to the latest version
!pip install --upgrade azureml-sdk
# For Jupyter notebook widget used in samples
!pip install --upgrade azureml-widgets
# For Tensorboard used in samples
!pip install --upgrade azureml-tensorboard
# Install Azure Machine Learning Reinforcement Learning SDK
!pip install --upgrade azureml-contrib-reinforcementlearning
Let’s return the Azure Machine Learning SDK version, it is quite handy in case you need to do some debugging.
import azureml.core
print('Azure Machine Learning SDK Version: ', azureml.core.VERSION)
It is a good idea to define which Azure tenant you want to use, so specify it with the use of the following code.
from azureml.core.authentication import InteractiveLoginAuthentication
InteractiveLoginAuthentication(force=False, tenant_id='<tenant_id>', cloud=None)
You can figure out your tenant id at the Azure Portal. Go to Azure Active Directory, and there you can find it at the Tenant information box. Now it is time to connect to the workspace that is just created. You can use a configuration, or you can specify it by defining the name of the workspace, the subscription id and the name of the resource group where you put the workspace and the compute target. You can find the subscription id at the Azure Portal, if you go to Subscriptions.
from azureml.core import Workspace# ws = Workspace.from_config()ws = Workspace.get(name="<workspace name>",
subscription_id='<subscription_id>',
resource_group='<name of resource group>')print(ws.name, ws.location, ws.resource_group, sep=' | ')
If the connection was successful, it will return the details of the workspace. The next step is to create a new experiment which will enable us to monitor the run.
from azureml.core import Experiment
exp = Experiment(workspace=ws, name='particle-multiagent')
Now we also create a cluster where the training is going to run. You can always change this code to use an existing cluster. In this code we also need a compute target for the Ray head, which is now a Standard D3 (CPU), which is why it is good enough to use 1 as maximum node.
from azureml.core.compute import AmlCompute, ComputeTargetcpu_cluster_name = 'cpu-cl-d3'if cpu_cluster_name in ws.compute_targets:
cpu_cluster = ws.compute_targets[cpu_cluster_name]
if cpu_cluster and type(cpu_cluster) is AmlCompute:
if cpu_cluster.provisioning_state == 'Succeeded':
print('Found existing compute target for {}. Using it.'.format(cpu_cluster_name))
else:
raise Exception('Found existing compute target for {} '.format(cpu_cluster_name)
+ 'but it is in state {}'.format(cpu_cluster.provisioning_state))
else:
print('Creating a new compute target for {}...'.format(cpu_cluster_name))
provisioning_config = AmlCompute.provisioning_configuration(
vm_size='STANDARD_D3',
min_nodes=0,
max_nodes=1) cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, provisioning_config)
cpu_cluster.wait_for_completion(show_output=True, min_node_count=None, timeout_in_minutes=20)
print('Cluster created.')
The good thing about this cluster is that it will scale down when it is not used. You are welcome to increase the nodes if you plan to run more than one experiments on this cluster. When the cluster is ready to use, this code will return the Cluster created message. We are going to use a customized Docker image where all the necessary software and Python packages are installed. The configuration for the training run is defined with the Environment class. Since we also want videos as results about the different runs of the particles, we need to set the interpreter_path too.
import os
from azureml.core import Environment
cpu_particle_env = Environment(name='particle-cpu')
cpu_particle_env.docker.enabled = True
cpu_particle_env.docker.base_image = 'akdmsft/particle-cpu'
cpu_particle_env.python.interpreter_path = 'xvfb-run -s "-screen 0 640x480x16 -ac +extension GLX +render" python'max_train_time = os.environ.get('AML_MAX_TRAIN_TIME_SECONDS', 2 * 60 * 60)
cpu_particle_env.environment_variables['AML_MAX_TRAIN_TIME_SECONDS'] = str(max_train_time)
cpu_particle_env.python.user_managed_dependencies = True
For training, we are going to use the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) algorithm, and as the name suggests, it will be able to train many agents at the same time. If the training runs over 3 hours, it will automatically stop, similarly if a -400 reward is given. We have to initialize ReinforcementLearningEstimator with different parameters that are necessary for the training.
from azureml.contrib.train.rl import ReinforcementLearningEstimator
from azureml.widgets import RunDetails
estimator = ReinforcementLearningEstimator(
source_directory='files',
entry_script='particle_train.py',
script_params={
'--scenario': 'simple_spread',
'--final-reward': -400
},
compute_target=cpu_cluster,
environment=cpu_particle_env,
max_run_duration_seconds=3 * 60 * 60
)
train_run = exp.submit(config=estimator)
RunDetails(train_run).show()
You are welcome to change the final reward parameter, when it is reached by the agent, the training is over. The -400 returns with a pretty good result, but if you want it to be better, training might take longer. Finally, we also want to see some more information about the experiment while it’s running, and a button is available to navigate you to the run details.

Go to the Child runs of the experiment, and choose the one that is running. If you navigate to the Outputs + Logs tab, you can find detailed logs about each trial in the driver log text file (azureml-logs folder).
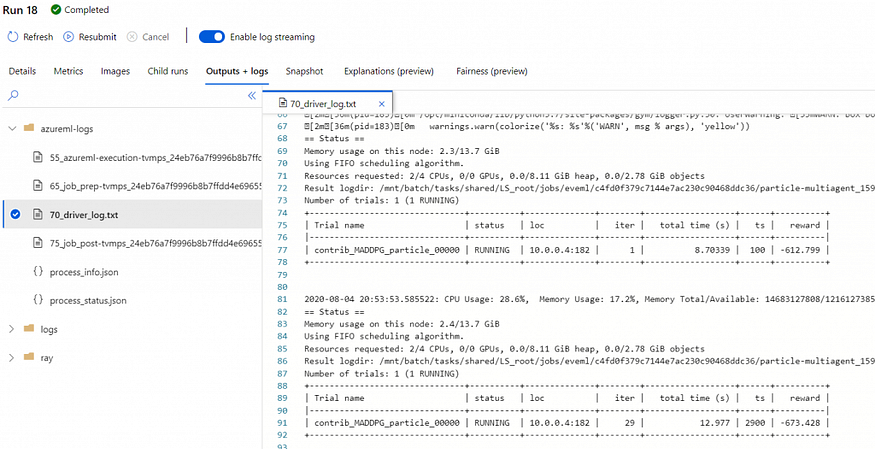
The generated videos are saved in the logs folder of the Outputs + Logs tab. You can download the videos from here, and take a look how the agents behave.
Let’s monitor the training run
Evaluation of a training is really important, and it is possible to reach videos about the different iterations. The code is going to download the generated videos and display it within the notebook.
from azureml.core import Dataset
from azureml.data.dataset_error_handling import DatasetValidationErrorfrom IPython.display import clear_output
from IPython.core.display import display, Videodatastore = ws.get_default_datastore()
path_prefix = './tmp_videos'def download_latest_training_video(run, video_checkpoint_counter):
run_artifacts_path = os.path.join('azureml', run.id)
try:
run_artifacts_ds = Dataset.File.from_files(datastore.path(os.path.join(run_artifacts_path, '**')))
except DatasetValidationError as e:
# This happens at the start of the run when there is no data available
# in the run's artifacts
return None, video_checkpoint_counter
video_files = [file for file in run_artifacts_ds.to_path() if file.endswith('.mp4')]
if len(video_files) == video_checkpoint_counter:
return None, video_checkpoint_counter
iteration_numbers = [int(vf[vf.rindex('video') + len('video') : vf.index('.mp4')]) for vf in video_files]
latest_video = next(vf for vf in video_files if vf.endswith('{num}.mp4'.format(num=max(iteration_numbers))))
latest_video = os.path.join(run_artifacts_path, os.path.normpath(latest_video[1:]))
datastore.download(
target_path=path_prefix,
prefix=latest_video.replace('\\', '/'),
show_progress=False)
return os.path.join(path_prefix, latest_video), len(video_files)
def render_video(vf):
clear_output(wait=True)
display(Video(data=vf, embed=True, html_attributes='loop autoplay width=50%'))import shutilterminal_statuses = ['Canceled', 'Completed', 'Failed']
video_checkpoint_counter = 0while head_run.get_status() not in terminal_statuses:
video_file, video_checkpoint_counter = download_latest_training_video(head_run, video_checkpoint_counter)
if video_file is not None:
render_video(video_file)
print('Displaying video number {}'.format(video_checkpoint_counter))
shutil.rmtree(path_prefix)
# Interrupting the kernel can take up to 15 seconds
# depending on when time.sleep started
time.sleep(15)
train_run.wait_for_completion()
print('The training run has reached a terminal status.')
You should run this code right after you started the training in order to get the videos inline. Since these videos are generated about each run, it is really interesting to watch, how it improves! The shown video looks similarly like on this picture:

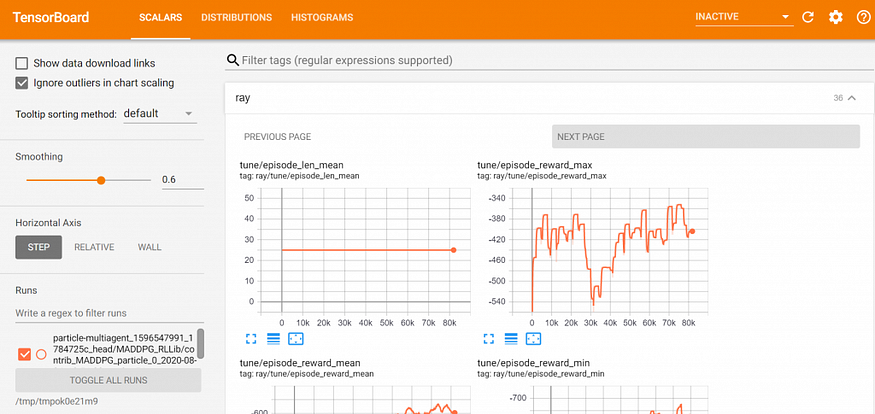
We can also monitor the trials in runtime via Tensorboard. This code should output a URL where you can find the dashboards.
import time
from azureml.tensorboard import Tensorboardhead_run = Nonetimeout = 60
while timeout > 0 and head_run is None:
timeout -= 1
try:
head_run = next(r for r in train_run.get_children() if r.id.endswith('head'))
except StopIteration:
time.sleep(1)tb = Tensorboard([head_run])
tb.start()
Click on the link, and after a few minutes you should be able to see the dashboard similarly like on this picture.
Contribution
The open source reinforcement learning tools welcome your contributions! Let us know if you have any issues, or feedback!
Github repo with RL samples
https://aka.ms/azureml-rl-notebooks
Resources and next steps
Blog article from //build
https://aka.ms/azureml-rl
YouTube — AI Show with Keiji
https://aka.ms/azureml-rl-aishow
Blog article about Paidia
https://aka.ms/GSLAIblog
Concept Documentation
https://aka.ms/amlrl-doc
Katja //build video talking about RL
https://channel9.msdn.com/Events/Build/2020/BDL205
Project Paidia: a Microsoft Research & Ninja Theory Collaboration – Microsoft Research
https://www.microsoft.com/en-us/research/project/project-paidia/