Responsible AI: Interpret-Text
Introduction
Artificial intelligence (AI) systems have a growing impact on people’s lives on an every-day-level, thus it is fundamental to protect people, understand models, and control ai systems. While machine learning (ML) services are constantly developing, Microsoft emphasizes the ethical principles that put people first, meaning that employees are working to ensure that AI develops in such way that can be benefitted in society while warranting people’s trust.
The object of the project is to bring explainability into often confusing and complex AI systems, since these can sometimes behave strange for various , not fully understood reasons. The tools discussed in this article can help developers to debug and fully understand their models.
Furthermore, it aims to increase the understanding of intelligent systems for end-users, thus building trust and power, which can assist users to make better decisions and accept AI solutions.
Interpretability
Interpretability assists data scientists to explain, debug and validate their models, thus helping to build trust towards the model. InterpretML is an open-source Microsoft package that incorporates ultra-modern machine learning interpretability techniques and can be viewed as a valid source for explaining blackbox (e.g. Deep Neural Network, LiMe) or glassbox models (e.g. Explainable Boosting Machine).
The azureml.interpret package supports developers using dataset formats such as numpy.array, pandas.DataFrame, iml.datatypes.DenseData, scipy.sparse.csr_matrix; furthermore, leverages libraries like LIME, SHAP, SALib or Plotly and offers new interpretability algorithms like Explainable Boosting Machine (EBM).
The interpretability package can be useful for any data scientist, specially start-ups and companies as an essential tool for model debugging, detect fairness issues, understand regulatory compliance and the model’s decisions to build trust amongst stakeholders and executives.
When you want to explore the behavior of the model by understanding feature importance, you can choose from a wide variety of techniques:
- Global: Explore overall model behavior and find top features affecting model predictions using global feature importance
- Local: Explain an individual prediction and find features contributing to it using local feature importance
- Subset: Explain a subset of predictions using group feature importance
- Feature Impact: See how changes to input features impact predictions with techniques like what-if analysis
Interpret-Text
Interpret-Text, the innovative interpretability technique for Natural Language Processing (NLP) models — that has been developed by the community — has been announced at Microsoft Build 2020, and currently only support topic classification.
This open-source tool allows developers and data scientists to explain their models globally or locally, to build a visualization dashboard that provides insights into their data, and to perform comparative analysis on their experiments while running them on different state-of-the-art explainers.
Before looking into the different explainers, let me take a step back. There are 2 broad classes of NLP approaches, classical ML and Deep Learning techniques.
Classical NLP Pipeline
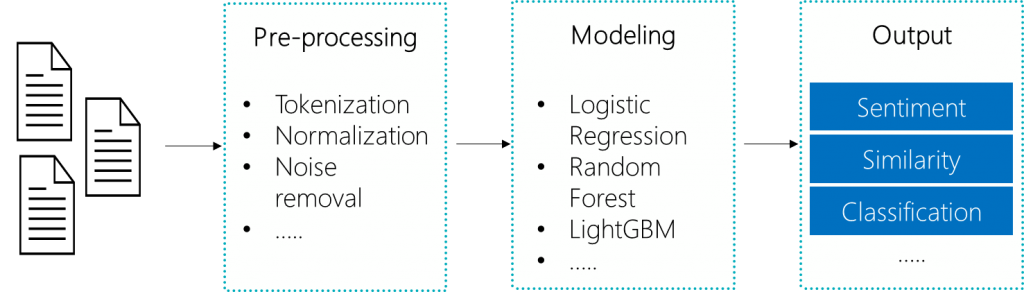
In classical techniques, the first step is pre-processing: which involves steps such as tokenization, normalization, noise removal. Then that processed data is fed into the model, which can be linear regression, LightGBM or random forest. The output depends on the scenario you are modeling for. For some of these approaches, the internal functionality is very well understood and as a result the user is confident in the explanations provided. However, these methods are widely adopted and easy to use, but are limited in their accuracies on real world data sets.
Deep Learning NLP Pipeline
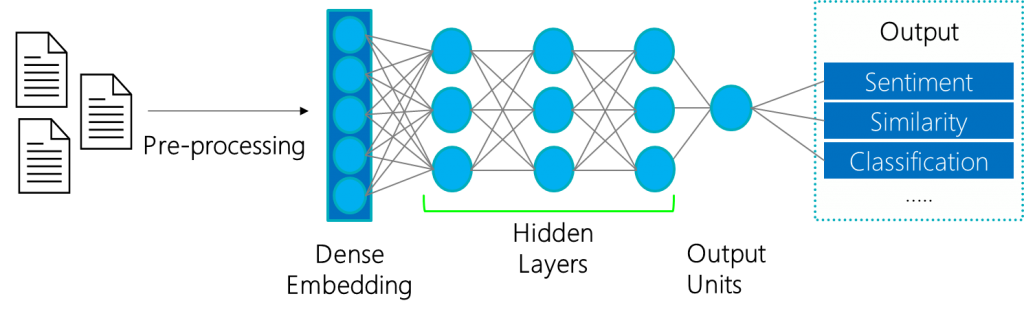
Recent advancements in NLP owe a lot to developments in deep neural networks such as Bidirectional Encoder Representations from Transformers (BERT). These models have very high accuracies on NLP tasks; however, they are black box models, and their decisions are quite difficult to understand. The research community has created a suite of state-of-the-art interpretable models ranging from post hoc analysis to plug ins during training. Though promising, these methods are hard to implement in practice and not as accessible to data scientists.
Microsoft has implemented three explainers, the classical and two state-of-the-art explainers.
Use Interpret-Text with the Classical Text Explainer
The Classical Text Explainer is an interpretability technique used on classical machine learning models, and covers the whole pipeline including text pre-processing, encoding, training and hyperparameter tuning, all behind the scenes.
As an input model, Classical Text Explainer supports two model families: scikit-learn linear models and tree-based models . Additionally, any models with similar layout and suitability for sparse representation can be used soon.
The API enables developers to extend or move around the different modules such as the pre-processor, the tokenizer, or the model, and the explainer still can pull in and use the tools implemented in the package.
If you want to understand how this explainer works, follow this link to the implementation:
Use Interpret-Text with the Unified Information Explainer
Unified Information Explainer can be used when a unified and intelligible explanation is needed about the transformer, pooler and classification layers of a particular deep NLP model.
Text pre-processing is handled by the explainer, sentences are tokenized by the BERT Tokenizer. At the time of writing the article, developer must provide Unified Information Explainer a trained or fine-tuned Bidirectional Encoder Representations from Transformers (BERT) model with samples of trained data. Support for Recurrent Neural Network (RNN) and Long short-term memory (LSTM) is also going to be implemented in the future.
Find out how to use the explainer by visiting the link below:
Use Interpret-Text with the Introspective Rationale Explainer
To generate an outstanding text fragment of important features for training a classification model, Introspective Rationale Explainer uses a generator-predictor framework. This tool predicts the labels and organizes the result, whether the words are useful (rationales) or should not be used for training (anti-rationales).
The API is designed to be modular and extensible, and can be used when a BERT or an RNN model needs to be explained. If the developer wants to define a personalized model, the pre-processor, the predictor and the generator modules should be provided by the developer.
Learn more about the usage of this explainer:
Contribution
This open-source toolkit actively incorporates innovative text interpretability techniques and allows the community to further expand its offerings. It creates a common API across the integrated libraries and provides an interactive visualization dashboard to empower its users to gain insights into their data.